2021年中國IT服務供應鏈數字化升級研究報告 驅動未來增長的核心引擎
引言:數字化浪潮下的IT服務供應鏈變革
隨著全球數字化轉型進程加速,中國IT服務行業正經歷著深刻的變革。2021年,在疫情常態化、新基建政策深化以及企業降本增效需求日益迫切的背景下,IT服務供應鏈的數字化升級已從可選項轉變為生存與發展的必選項。本報告旨在深入剖析2021年中國IT服務供應鏈管理服務的數字化升級現狀、核心驅動力、關鍵技術應用、面臨的挑戰以及未來發展趨勢,為行業參與者提供戰略參考。
第一章:現狀與背景——數字化升級的必然性
2021年,中國IT服務市場規模持續擴大,涵蓋IT咨詢、系統集成、運維服務、軟件開發等多個領域。傳統的供應鏈管理模式,因其信息孤島、響應遲緩、協同效率低、成本高企等問題,已難以滿足市場對敏捷、透明、智能服務的需求。客戶對個性化、全生命周期服務的期待不斷提升,倒逼服務提供商必須通過數字化手段重塑供應鏈。政策層面,“十四五”規劃明確提出要推進產業數字化,供應鏈創新與應用成為重點,為IT服務供應鏈升級提供了強有力的政策支持。
第二章:核心驅動力——多維因素共促轉型
- 市場需求拉動:企業客戶數字化轉型項目復雜度增加,要求IT服務商具備快速資源調配、精準交付和持續運維的能力,數字化供應鏈是實現這一能力的基礎。
- 技術成熟推動:云計算、大數據、人工智能、物聯網及區塊鏈等技術的成熟與成本下降,為構建智能、可追溯、可預測的供應鏈提供了技術工具箱。
- 競爭壓力使然:行業內部競爭加劇,利潤空間受到擠壓。通過數字化提升供應鏈效率、降低運營成本、優化庫存管理,成為構建核心競爭力的關鍵。
- 風險管理需求:全球芯片短缺、物流波動等外部不確定性事件凸顯了供應鏈韌性的重要性。數字化工具能夠增強供應鏈的可見性與抗風險能力。
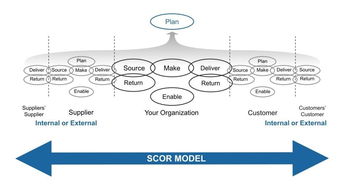
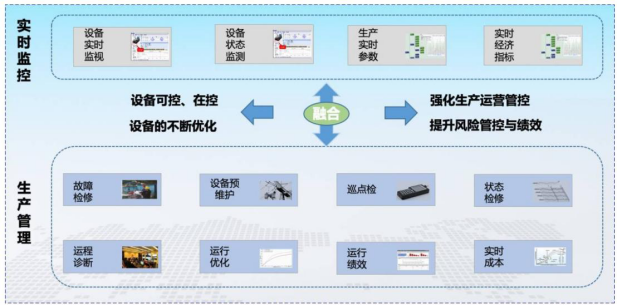
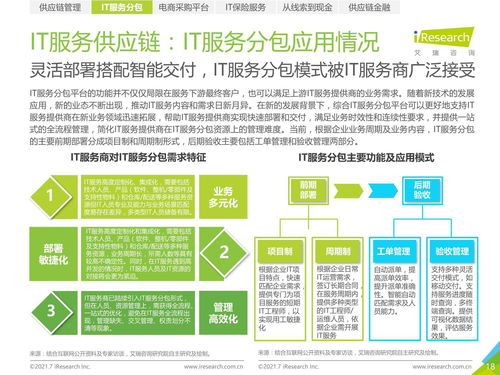
第三章:關鍵技術應用與場景實踐
- 云計算與SaaS平臺:基于云的供應鏈管理平臺成為主流,實現了資源(人力、設備、軟件許可)的集中化、彈性化調度與協同,尤其支持了遠程交付和分布式團隊協作。
- 大數據與智能分析:通過匯聚歷史項目數據、資源利用率數據、市場數據等,進行需求預測、智能派單、風險預警和績效分析,實現從經驗驅動到數據驅動的決策轉變。
- 人工智能與自動化:AI應用于工程師技能匹配、智能排程、自動化測試與部署、客服機器人等領域,大幅提升服務交付的自動化水平與精準度。
- 物聯網與資產追蹤:對服務器、網絡設備等硬件資產進行全生命周期物聯網追蹤,實現資產狀態實時監控、定位及預測性維護。
- 區塊鏈技術探索:在供應鏈金融、服務合同管理、資質與成果認證等方面進行試點,旨在建立不可篡改的信任機制,提升多方協作效率。
第四章:面臨的挑戰與瓶頸
- 數據整合與治理難題:企業內部及與合作伙伴間存在數據標準不一、系統孤島問題,數據質量與完整性是發揮數據價值的前提。
- 技術與人才壁壘:數字化升級涉及多技術融合,對既有IT架構和人員技能提出挑戰,復合型人才短缺。
- 初期投入與ROI衡量:數字化改造需要可觀的前期投入,而其回報周期較長且難以量化,影響企業決策。
- 安全與隱私顧慮:供應鏈數據集中化帶來更高的數據安全和客戶隱私保護風險。
- 生態協同阻力:數字化供應鏈要求與上下游伙伴深度協同,但不同企業間數字化水平參差不齊,形成協同壁壘。
第五章:未來發展趨勢與展望
- 服務化與平臺化融合:供應鏈管理本身將更多以“服務”形式提供,行業可能出現集資源整合、智能匹配、交易保障于一體的開放性平臺。
- 端到端全鏈路可視化:從商機、采購、交付到運維的全程實時可視化將成為標配,極大提升客戶體驗與管理精度。
- 預測性與自適應能力:基于AI的供應鏈將具備更強的需求感知、風險預測和自主優化調整能力,走向“智能自適應”。
- 綠色與可持續發展:數字化工具將用于優化物流路線、提升資產復用率、降低能耗,助力IT服務供應鏈的綠色轉型。
- 生態共同體構建:領先企業將牽頭構建數字化供應鏈生態,通過標準與接口開放,連接更廣泛的合作伙伴,實現價值網絡共贏。
結論
2021年是中國IT服務供應鏈數字化升級的關鍵之年。這一進程不僅是技術工具的應用,更是一場深刻的商業模式與管理理念變革。成功實現數字化升級的IT服務企業,將構建起以數據為血液、以智能為大腦、以網絡為肢體的高效、韌性、客戶-centric的新型供應鏈體系。面對挑戰,企業需制定清晰的數字化戰略,分步實施,夯實數據基礎,培育數字文化,并積極擁抱生態合作。數字化供應鏈必將成為IT服務企業贏得市場競爭、實現高質量發展的核心引擎。
如若轉載,請注明出處:http://m.c87v7.cn/product/78.html
更新時間:2026-06-18 11:04:57